In-context learning is a promising paradigm that utilizes In-context examples as prompts for the predictions
of large language models. These prompts are crucial for achieving strong performance. However, since the
prompts need to be sampled from a large volume of annotated examples, finding the right prompt may result
in high annotation costs. To address this challenge, this paper introduces an influence-driven selective
annotation method that aims to minimize annotation costs while improving the quality of In-context examples.
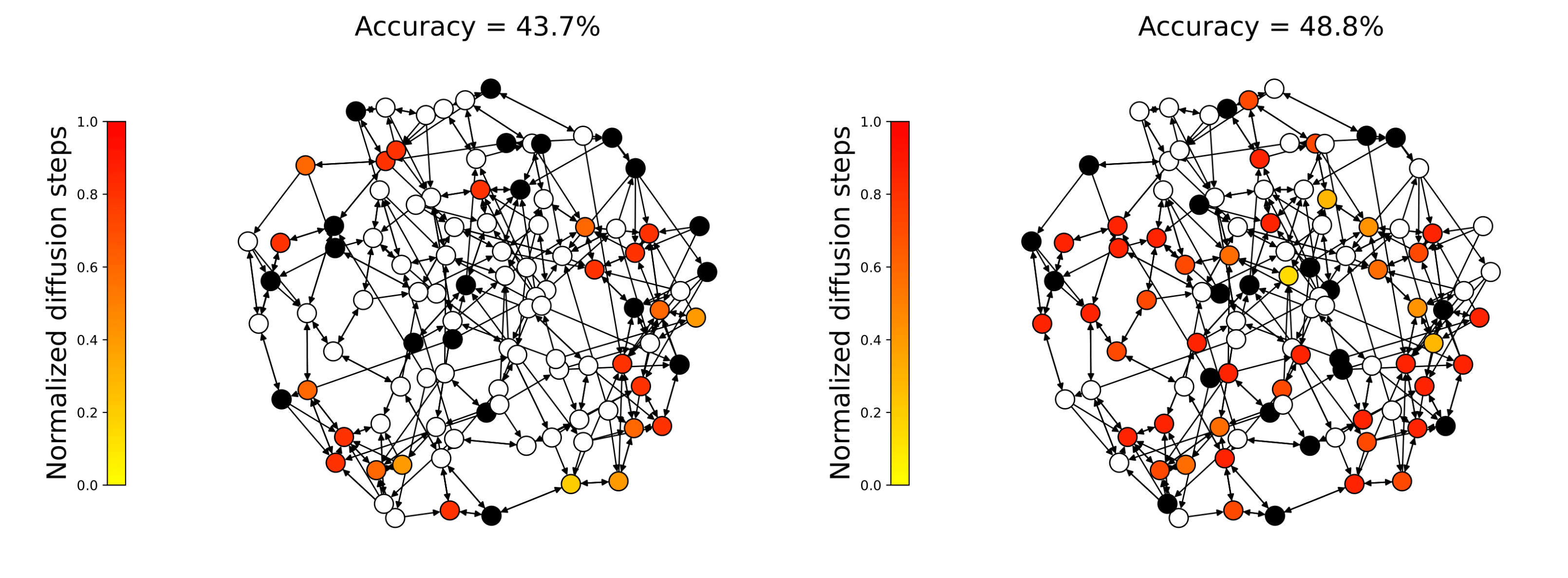
The essence of our method is to select a pivotal subset from a large-scale unlabeled data pool to annotate
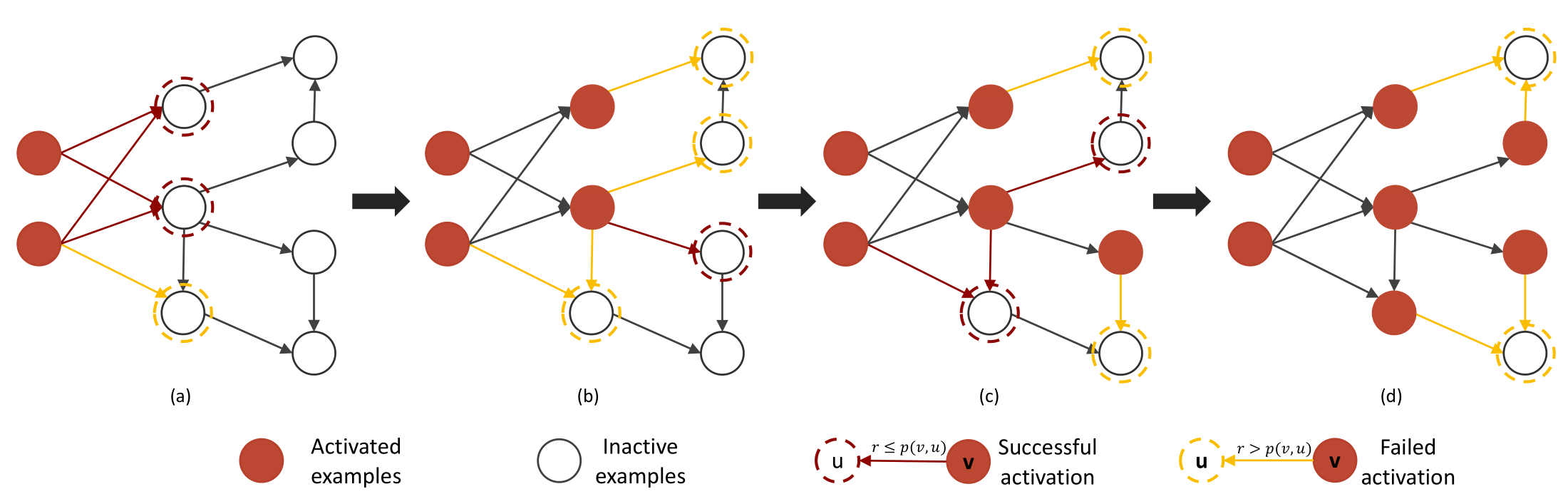
for the subsequent sampling of prompts. Specifically, a directed graph is first constructed to represent
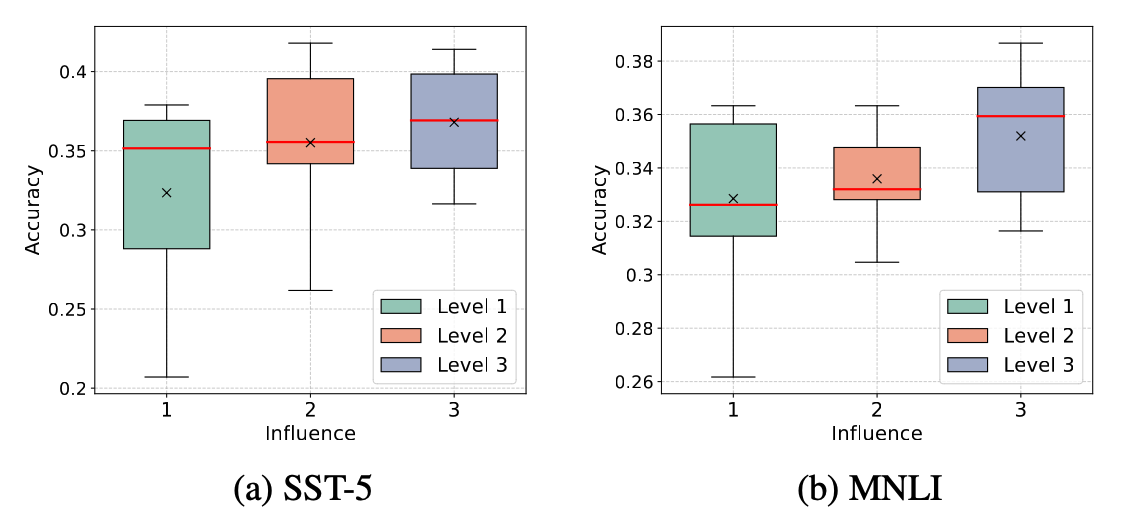
unlabeled data. Afterward, the influence of candidate unlabeled subsets is quantified with a diffusion
process. A simple yet effective greedy algorithm for unlabeled data selection is lastly introduced. It
iteratively selects the data if it provides a maximum marginal gain with respect to quantified influence.
Compared with previous efforts on selective annotations, our influence-driven method works in an
end-to-end manner, avoids an intractable explicit balance between data diversity and representativeness,
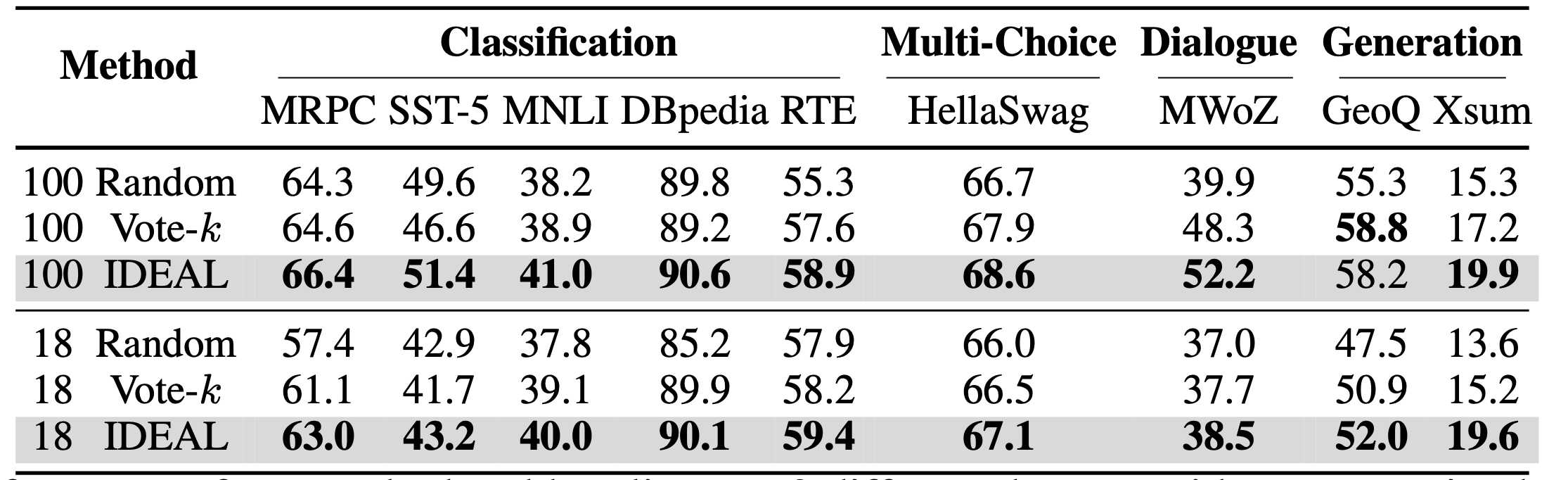
and enjoys theoretical support. Experiments confirm the superiority of the proposed method on various
benchmarks, achieving better performance under lower time consumption during subset selection.